The adventure continues high above as we delve deeper into our CanSat project. While our primary mission captures atmospheric data, our secondary mission involves exploring the intricacies of depth estimation using stereo cameras and the power of machine learning. At the heart of this endeavor is a machine-learning model, specifically a convolutional neural network (CNN) that brings a semblance of depth perception to a machine. Let's explore how this ML model works and how it's the bedrock of our CanSat's secondary mission.
Diving into depth estimation
For our CanSat, understanding the 3D structure of the environment below is critical for tasks such as navigation and identifying landing zones. Traditional algorithms struggle to keep up with the variable lighting, vast landscapes, and complex motion patterns experienced during a descent. That's where our ML model steps in, relying on a type of CNN designed for analyzing stereo images to infer depth information.
We have decided to focus in on the depth estimation principle of stereo vision, which is similar to how human eyes perceive depth. Just as our eyes capture slightly different images due to their horizontal separation, stereo cameras record two distinct images from slightly offset viewpoints. The basis of depth estimation lies in finding the corresponding points—features such as edges, corners, or distinctive textures—in these two images, and then measuring the disparity, which is the difference in the horizontal positions of these points across the image pair. The greater the disparity, the closer the object is to the camera system. By using geometry and the known distance between the two cameras, we can calculate the depth or distance of these objects from the cameras. This data creates a 3D map of the CanSat's surroundings, allowing it to gauge the terrain and distances during its descent.
Camera view
Unlike other depth estimation methods, this does not require any onboard processing in the can, only requires two pictures to be transmitted to run the algorithm on, and does not require predictable movement of the can as it falls.
However, our specific situation poses a challenge. One issue is the ground texture: traditional depth estimation algorithms may struggle to match the ground details from one camera to another due to the complex nature of the texture of grass and other ground features. Furthermore, our CanSat will be estimating depth from a great distance, beyond that which traditional algorithms are designed for. At these distances, the difference between a variation of position of an object by one or two pixels corresponds to a significant difference in depth. Therefore, we need a system capable of using the collected data to infer depths it may not be able to directly calculate.
The mechanics of machine vision
ML models, particularly CNNs, thrive where rule-based programming might stumble among the nuanced and variable patterns of vision data. A CNN is adept at image-related tasks. It can learn to identify patterns and structures in visual data. This process allows CNNs to autonomously learn distinctive features from the images without being explicitly programmed to look for them.
2D CNNs work by sliding filters over an image, analysing small pieces or patches of the image at a time. Each filter captures local features such as edges, textures, or patterns. When a filter is applied to an image, it produces a new image, called a feature map, that emphasises the detected features and supresses others. These features are then passed through multiple layers of the network. Each layer applies its own set of filters, progressively building up a more abstract understanding of the image's content. For example, early layers might detect simple features while later layers might detect more complex features such as shapes or objects.
3D CNNs take this a step further by not just looking at individual 2D features but analyzing the data across three dimensions (in our case, analysing each pixel across multiple possible disparity values). This 3D perspective allows the network to understand depth and spatial relationships between objects in the scene.
Together, these networks form a stereo depth estimation model that interprets a pair of two-dimensional images and extracts three-dimensional insights.
Harnessing the power of stereo vision, our CanSat captures pairs of images from two slightly different views, mimicking the distance between human eyes. The model then applies the trained CNNs to these images, identifies which features correspond to one another in both views, and calculates the disparity (or the distance between the same feature on two images). This disparity is then translated into depth information using information about the camera setup.
Custom dataset generation
As there are very few existing datasets available to train our machine learning model on (and none at all with the same camera setup our can will use), we created a custom dataset using Blender, the open-source 3D creation suite. Our journey began with generating random terrains. These digital landscapes were designed to mimic a variety of real-world terrains our CanSat might encounter during its missions.
The process involves a few key steps:
-
Setting up Cameras: To create stereo image pairs akin to binocular vision, we placed virtual cameras in Blender at fixed points mimicking the stereoscopic setup. This arrangement mimics the average human eyes' separation, ensuring the data generated is close to what our stereoscopic vision system would perceive.
-
Rendering Images: With the virtual environment set, we took virtual 'pictures' from both camera perspectives. These high-quality images serve as the left and right views of our stereo pairs.
-
Extracting Depth Maps: Blender’s ability to create Z-depth maps allowed us to extract accurate depth information for each pixel in the image. These maps provide ground-truth data for training our CNNs and assessing their depth estimation accuracy.
-
Data Augmentation: To further enhance our dataset, we applied data augmentation techniques such as adjusting lighting conditions and adding random noise. This step ensures our model is robust to various environmental factors.
The result is a comprehensive and realistic training ground for our machine vision model.
Model training and results
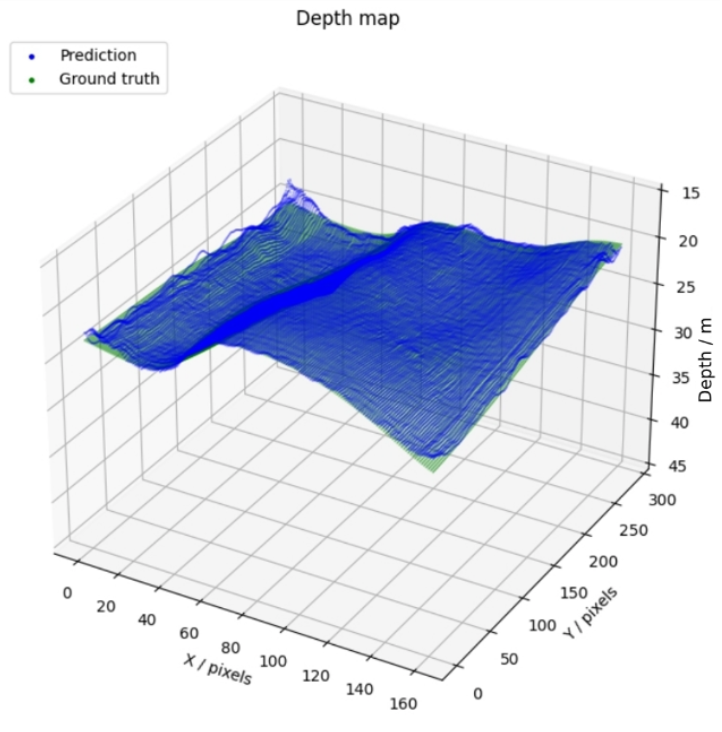
Training a CNN, particularly with a custom dataset, involves feeding the network thousands of image pairs alongside their corresponding depth maps. Over time, the model fine-tunes its parameters to minimize the difference between its depth predictions and the actual depth values.
Our training process involved several iterations, tweaking the number and size of layers and filters, and tweaking the learning rate (to what extent the model modifies itself in response to the training data) to find the optimal configuration for our depth estimation challenge.
The results were promising. Our model demonstrated a remarkable ability to infer depth even in complex scenarios that traditional algorithms struggled with. Instances where ground textures were particularly challenging or where objects were at a considerable distance saw significant improvement in depth estimation accuracy.
Next steps
The next stage of our CanSat project involves designing the hardware of our can. In our next post, we will explore the iterative design process of creating the 3D model of our can, discuss our chosen materials, and give an insight into the 3D printing process we used to manufacture our can.